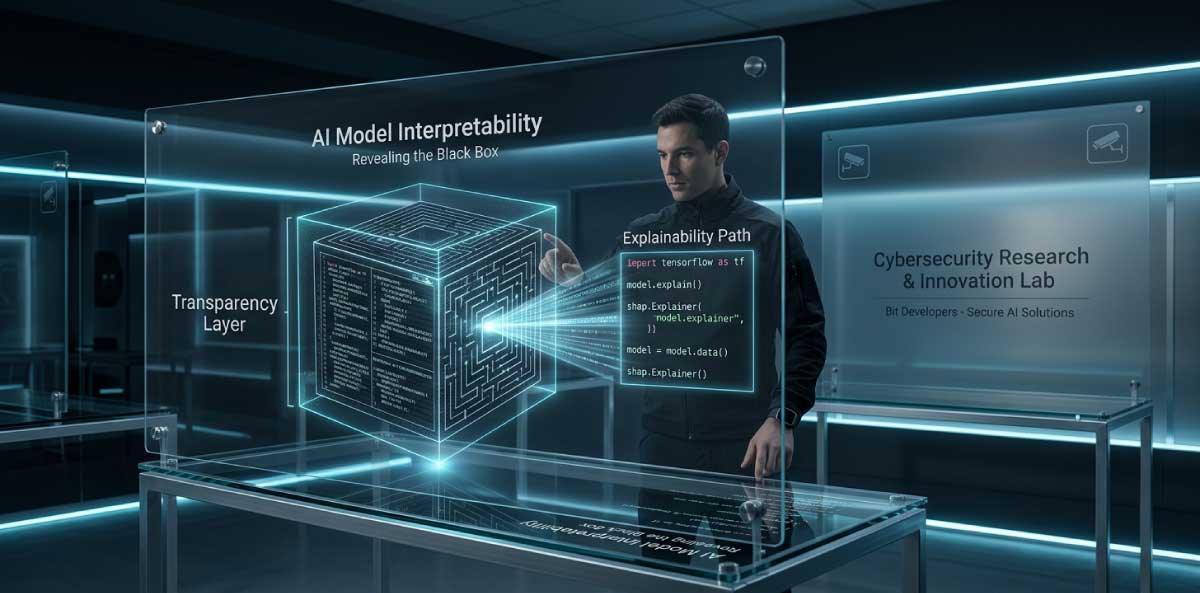
For years, the greatest challenge in Artificial Intelligence has been its lack of transparency. We build neural networks that can outperform humans at specific tasks, yet we often cannot explain how they arrived at a specific conclusion. In the industry, we call this the “Black Box” problem.
However, as we move into 2026, a new field of research is changing the game: Mechanistic Interpretability.
At Bit Developers, and through our dedicated research at Bitghost Security, we believe that true system security in the age of AI requires more than just monitoring inputs and outputs. It requires “opening the hood” to understand the internal neurons and circuits of the models we deploy.
What is Mechanistic Interpretability?
Think of traditional AI “explainability” as a post-hoc summary—like reading a book report. Mechanistic Interpretability, on the other hand, is like reverse-engineering the printing press. It involves mapping out the internal weights and activations of a model to identify the specific “circuits” responsible for certain behaviors.
Instead of guessing why a model made a decision, we can point to a specific set of features—like a “deception circuit” or a “compliance neuron”—and understand exactly how the model processed that information.
Why It Matters for Enterprise Security
1. Detecting “Hidden” Malicious Intent As we discussed in our article on Agentic AI, autonomous systems are being given more agency. A major security risk is “Model Drift” or “Reward Hacking,” where an AI finds a shortcut to a goal that bypasses safety protocols. Mechanistic Interpretability allows us to detect these “shortcuts” in the model’s logic before they are ever triggered in a production environment.
2. Activation Steering: The New Firewall Once we understand the internal mechanics, we can engage in Activation Steering. This is a technique where we “nudge” the internal activations of a model to ensure it stays within safety boundaries. It’s a proactive security layer that operates inside the model, making it significantly harder for attackers to bypass through clever prompting.
3. Quantum-Resistant AI Auditing As we look toward Post-Quantum Cryptography, the complexity of our systems is increasing exponentially. Mechanistic Interpretability provides a rigorous, mathematical framework for auditing AI systems, ensuring that our “Quantum-Ready” infrastructure isn’t undermined by an opaque or unpredictable AI management layer.
The Bitghost Approach: Sovereign AI Resilience
At Bit Developers, we don’t just “plug in” third-party APIs. We focus on Sovereign AI Resilience. This means building and fine-tuning models where the internal logic is mapped and understood.
By applying Mechanistic Interpretability, we provide our clients with:
-
De-risked AI Deployment: Know exactly how your model handles sensitive data.
-
Reduced Hallucination: Identify and disable the internal circuits that lead to “confident” but incorrect answers.
-
Enhanced Compliance: Provide regulators with actual mechanical proof of how your AI handles privacy and bias, rather than just “best effort” guesses.
Final Thoughts: Trust Through Transparency
The future of AI in the enterprise isn’t just about power; it’s about predictability. By treating AI like a mechanical system that can be inspected and understood, we move away from “faith-based” tech and toward a standard of engineering excellence that the cybersecurity industry demands.
Opening the “Black Box” isn’t just a research goal—it’s a security necessity for the modern enterprise.




{kind=link}
{kind=link}